
브라우저(Browser)?
우리가 흔히 아는 브라우저로는 대표적으로 애플의 Safari, 구글의 Chrome, 마이크로소프트의 IE(지금은 사망), Edge 등 있지만 firefox, Opera, Dolphin 등이 있다.
브라우저의 기본 구조
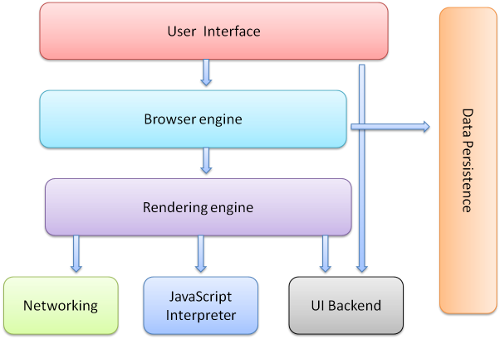
1. 사용자 인터페이스(User Interface)
- 주소 표시줄, 이전/다음 버튼, 북마크 메뉴 등..
- 요청한 페이지를 보여주는 창을 제외한 부분을 보여준다.
2. 브라우저 엔진(Browser Engine)
- 사용자 인터페이스와 렌더링 엔진 사이의 동작을 제어한다.
3. 렌더링 엔진(Rendering Engine)
- 요청한 컨텐츠를 표시한다.
- HTML을 요청할 경우 HTML과 CSS를 파싱(해석)하여 화면에 표시한다.
4-1. 통신(Netwroking)
- HTTP 요청과 네트워크 호출에 사용한다.
- 플랫폼의 독립적인 기능이고, 각 플랫폼의 하부에서 실행된다.
4-2. 자바스크립트 해석기(JavaScript Interpreter)
- 자바스크립트 코드를 해석하고 실행한다.
4-3. UI 백엔드(UI Backend)
- 콤보 박스나 글 입력 폼등 기본적인 장치를 그린다.
5. 자료 저장소 (Data Persistence)
- 자료를 저장하는 계층으로 쿠키나 로컬 스토리지등의 자료가 저장된다.
- 주로 하드디스크에 저장되며 HTML 명세 등도 이곳에 저장된다.
렌더링 엔진

브라우저에는 각각의 렌더링 엔진이 있으며 대표적으로는 모질라(Mozhila)에서 직접 개발한 Gecko 엔진과, 사파리(Safari)의 Webkit 엔진, 크롬(chrome)의 Blink엔진이 있다. 기본적으로 렌더링 엔진의 역할은 HTML, XML 등 문서와 이미지 등 요청 된 내용을 화면에 표시하는 역할을 한다.
브라우저 동작 방식
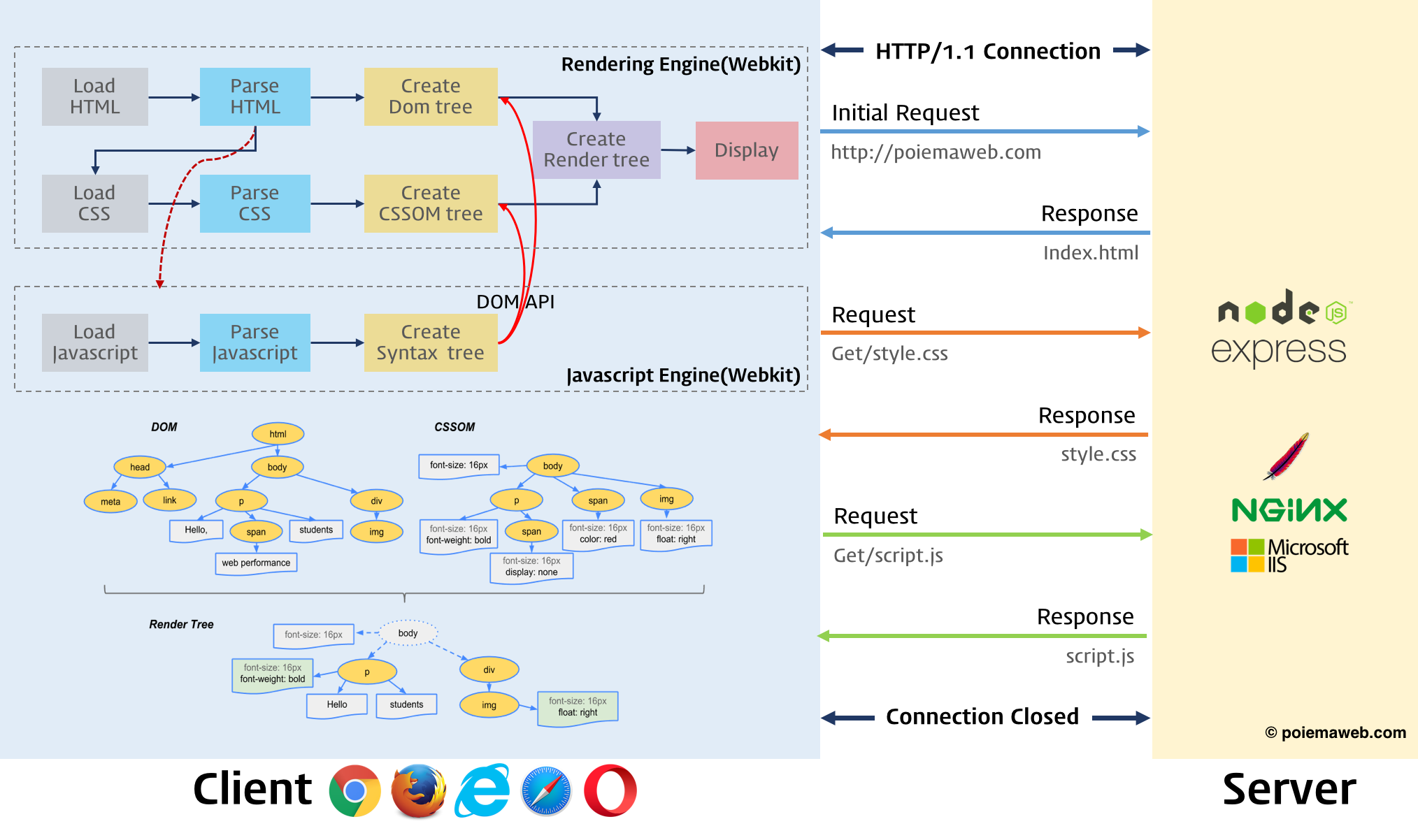
브라우저의 핵심 기능으로 사용자가 참조하고자 하는 웹페이지를 서버에 요청(Request)하고, 서버의 응답(Response)를 받아 브라우저에 표시한다. 브라우저(Client)는 서버(Server)로부터 HTML, CSS, JavaScript, 이미지 파일 등을 응답 받는다. 여기서 HTML과 CSS는 렌더링 엔진의 HTML Parser, CSS Parser를 통해 HTML의 구문 분석을 통해 DOM 트리로, CSS의 구문을 분석하여 CSSDOM 트리로 변환한 다음 렌더(Render) 트리로 결합시킨다.
반면 자바스크립트(JavaScript)는 렌더링 엔진이 아닌 자바스크립트 엔진(대표적으로 크롬 V8, Webkit) 으로 처리한다. HTML Parser는 <script> 태그를 만나면 자바스크립트 코드를 실행하기 위해 DOM 생성 프로세스를 중지하고 자바스크립트 엔진으로 제어권한을 넘긴다. 제어권을 넘겨받은 엔진은 <script> 태그 내의 자바스크립트 코드나 src 어트리뷰트에 정의된 자바스크립트 파일을 로드하고 파싱(Parshing)하여 실행한다.
자바스크립트 실행이 모두 완료되면 HTML Parser로 권한을 넘겨서 브라우저가 중지했던 시점부터 DOM생성을 재개한다.
출처1-HTML5Rocks
출처2-웹 브라우저 작동원리
'FE BE 개발 메모장 > Client Server Architecture' 카테고리의 다른 글
| 크로스 브라우징(Cross Browsing) 알아보기 (0) | 2021.06.15 |
|---|---|
| HTTP 세션(session) (0) | 2021.03.06 |
| 쿠키(Cookie) (0) | 2021.03.05 |
| HTTPS (0) | 2021.03.04 |
| REST API에 대해 이해하기 (0) | 2021.02.05 |